Counting Lines, Fast and Slow
It’s fun to take a simple problem and see how far we can take it in terms of performance. Almost always, after you think you’ve exhausted all options, there is someone who can point out one more thing that is all the more esoteric the less there seems left to squeeze. Inevitably, that optimization will be harder to grok by just reading the code.
Still, that “A ha!” moment is always worth digging through to understand what is going on.
The dawning comprehension comes with understanding how something really works under the hood. Then, maybe you’re in a meeting or taking a shower, there is the realisation that you can use this with something else you were working on. That in turn rejuvenates your interest in something you parked or thought you were done with; maybe sparks you interest in something you never know you cared about.
Scope
We’ll write a command line program using Crystal1 that
- takes a file path as its only argument,
- assumes all files are UTF-8 encoded2,
- counts the number of lines in the file by counting the occurrences of byte
0x0a(aka'\n'), and - prints out the number of lines and nothing else.
For example:
|
|
We’ll start as simple as possible and work our way towards getting it to run as fast as possible.
A simple line counter
When writing a quick and dirty script to count lines, the easiest, and perhaps most idiomatic, approach is to open the file and iterate through all the lines while keeping a counter.
|
|
Here’s the timing when benchmarking3 this program:
|
|
Baseline
wc as baseline.
Unix platforms (and others)4 have had the wc command that prints word, line and byte counts for text files. I’ll be using wc -l, the option that counts only lines, as a baseline for comparison with the program versions in this article.
While I compare every version of the evolving line counter with
wc -l, my intent is not to denigratewcbut instead pay tribute to a venerable word and line counting workhorse in the command line tools arsenal.
|
|
wc -l is ~2.2x faster than our naive first attempt, which is not bad for the simplest first attempt.
Characters vs lines
Since each line is a String made up of Char values (characters), let’s try counting the newline characters by iterating over the characters from the file using IO#each_char.
|
|
Here’s the timing when benchmarking this version:
|
|
Ouch. Clearly we need to dig into how #each_line is implemented to figure why iterating through characters is so much slower.
Bytes vs characters
Digging into the standard library’s source code, Crystal’s #gets method, used by #each_line to read and yield each line, has optimizations for when the delimiter (newline or '\n' in our case) is an ASCII byte. Since we are counting lines in UTF-8 files, we know that a newline is a solo byte that we can look for in UTF-8 text without worrying about multi-byte processing.
Let’s try scanning bytes instead of characters using #each_byte, ignoring the overhead of looking for and handling potential multi-byte encoding that happens behind the scenes when we iterate over Char values.
|
|
Here’s the timing when benchmarked:
|
|
We are back on track, and still as simple. We’re doing better than iterating over lines (both in time and space), and now wc -l is only ~1.8x faster.
Byte slices
Looking deeper into Crystal’s standard library, IO#each_byte calls IO#read_byte for every byte that it yields, in turn dealing with buffering and other book-keeping, adding overhead to every byte we inspect. Since it certainly makes sense to buffer the reading, but we don’t need anything more that to inspect the bytes, let’s try managing our own buffering by reading chunks of bytes into a buffer that we allocate and then iterating over the bytes in each chunk.
|
|
Here’s the timing when we benchmark it:
|
|
Nice. With the 512KB buffer5 into which we load portions of the file to count the newline bytes, we’re now running slightly faster than wc -l on the same input. Even though we stopped thinking of “lines” back when we started scanning characters and bytes, this version is starting to look less intuitive at first glance. It’s still small enough though that we can understand it if we stare at it a little.
Long “words” vs bytes
At this point we’re not that very different from how wc -l works. If we want to continue with our sequential approach, to get more speed we will need to change how we find and count the newline bytes in the buffer.
Current mainstream processers are capable of at least 32-bit operations, and most support 64-bit operations. Can make the counting run faster by using “long word” maths on 32 bits (or 64 bits) of data at a time?
The Linux kernel has an optimized implementation of memchr()6 that uses a combination of long integer maths and bitwise operations to find a single byte in a long word. This approach counts trailing zero bits to identify the “first” occurrence of a byte after performing some bitwise transformations that leave behind a 1 bit for each byte that matches the byte memchr is looking for.
We can however use #popcount, a CPU instruction which Crystal exposes for integers, to count all the occurrences of the 1 bit.
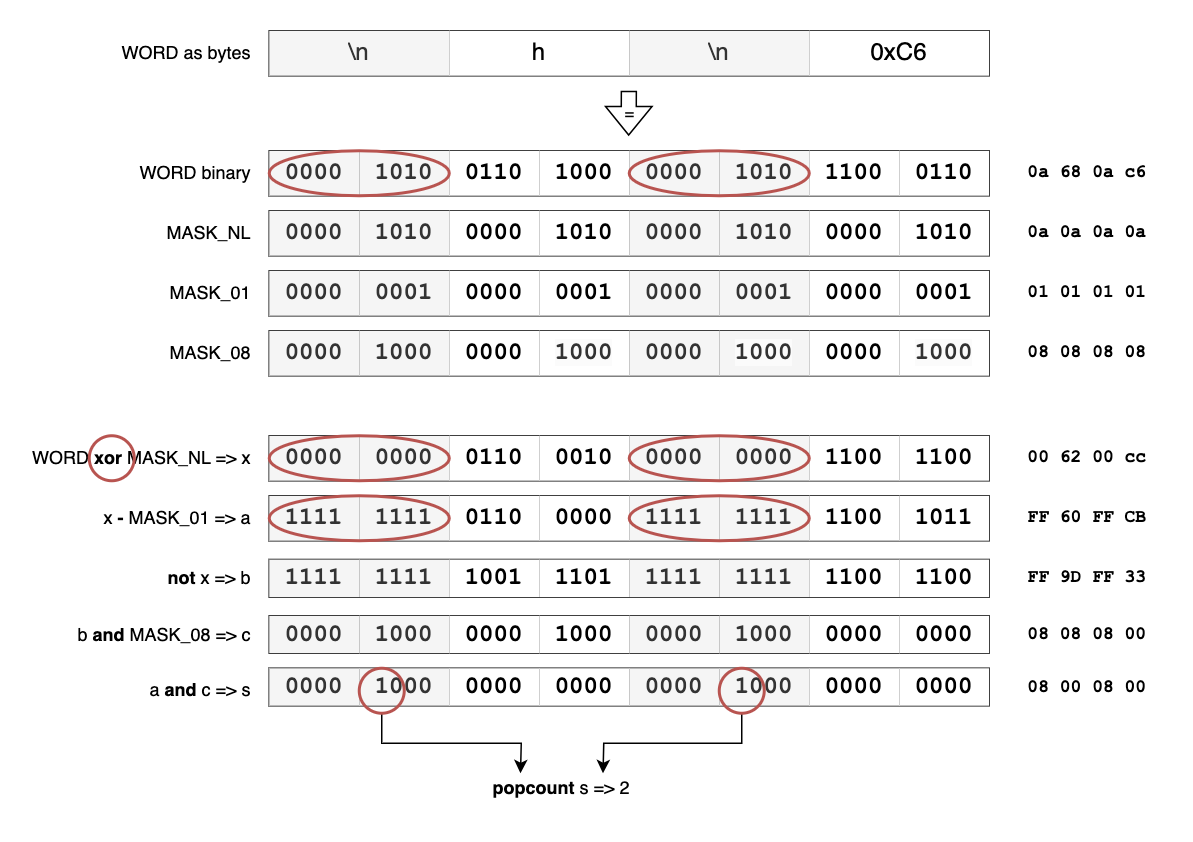
See the example in the illustration above to get a sense of how this works, where the XOR is used to zero out the byte we’re looking for and then we invert those zeros to make a mask for selecting the the 0x08 byte so we can get a 1 bit for every matching newline.
Since we are reading byte buffers, and we are working with Crystal, we will need to use some “unsafe” operations to make sure we can iterate over long words, in effect “casting” a byte pointer to a pointer to a buffer of longer integers. After processing the long integers, near the end of the buffer we need to account for any remaining bytes depending on the file size, which we have to check individually.
I’ve isolated the optimization into a function that uses (and hides) unsafe pointers to read 32-bit “words” and perform bitwise maths to count the number of newline bytes in a buffer of n bytes:
|
|
This will return the number of newline bytes in a given byte buffer, and calling this we have the following main loop:
|
|
Here’s the timing when we benchmark this version:
|
|
Boom.
Using 32-bit wide maths to count newlines four bytes at a time and taking advantage of the CPU’s ability to perform 32-bit maths at least as fast as it performs 8-bit maths, we can now count lines 4.3x faster than wc -l.
Longer “words”
What about using 64-bit maths? After all most if not all of our personal computers today use 64-bit processorts, and I wanted to know what improvement I could get processing 8 bytes at a time. Here’s the modified line counter that uses 64-bit maths:
|
|
Modifying the main loop to use #count_newlines_by_word8 function instead, we get the following timing from the benchmark:
|
|
It’s slightly faster on my laptop with a 64-bit processor, though not as much as you might expect after the 4x improvement earlier. We are now 4.7x faster then wc -l.
Intermediate conclusion
The line-counter now counts half a billion lines in a file of over 6GB in well under two seconds almost 5x faster than wc -l which took a little over 7 seconds.
It’s sequential, utilizing just one of the 6 cores on my benchmarking machine; and it uses a fixed amount of memory (512KB) regardless of file size.
While there are a few more avenues we could explore (e.g. file loading using memory mapping, SIMD intrinsics) to improve sequential performance, at this point I am more curious about the benefits of parallelizing the line counter.
Concurrent IO and Compute
With the most recent optimizations we have reached a point where reading from the file dominates the time spent. Using different chunk sizes has no meaningful impact since the corresponding increase in I/O time continues to overwhelm the compute time.
To go faster we need to consider decoupling the compute and the I/O. Since reading from a file is a blocking operation in Crystal’s standard libaray, running them concurrently to take advantage of the multiple cores in our CPUs should give us a boost. Knowing that reading from the file takes as much or more time than counting the lines in a chunk, the next attempt uses two threads: one for reading chunks and the second one for counting. To ensure we keep both threads busy we do the following:
- Setup three channels:
- Let’s call one “Ready for IO” which is used by the “Reader” to detect when a buffer is not in use so that the “Reader” can read from the file to fill it.
- The next one is “Ready for Counting”, which is used by the “Counter” to detect when a buffer is available for counting lines.
- The last one is “Done Counting”, which is used by the “Counter” to send the line count when it has no more buffers to count.
- We pre-populate the “Ready for IO” channel with two empty 512K buffers to ensure that after one buffer has been read, we can read the second one while the first is being counted.
- Use
spawnto setup the “Counter” fiber which can be run in its own thread:- The “Counter” repeatedly waits on the “Ready to Count” channel until, either it receives a buffer to count or it receives a
nilto indicate there is no more work.- If there’s a buffer, we count the lines and update the line counter
- Otherwise we send the line count to the “Done Counting” channel
- The “Counter” repeatedly waits on the “Ready to Count” channel until, either it receives a buffer to count or it receives a
- The main body runs in its own thread and is the “Reader” which, after opening the file
- iterates over the size of file in buffer-sized steps, and
- waits on the “Ready for IO” channel to retrieve a buffer to fill, and
- after reading from the file sends the buffer (with the number of bytes read) to the “Ready for Counting” channel.
- When the whole file has been read, the “Reader” countin channel waits on the “Done Counting” channel to receive the line count to print.
Here’s the source code, which is now more complicated than our previous attempts:
|
|
This program needs to be compiled with the
-Dpreview_mtoption to ensure multi-threading is enabled at runtime.
Running this we get the following peformance result:
|
|
Using one thread to read chunks from the file while at the same time another thread counts the lines in each chunk, the program is now ~6.9x faster than wc -l, and ~1.49x faster than our fastest sequential version.
More bigger buffers
The above implementation has two constants: IO_CAP for the number of buffers we pre-load, and IO_BUFSZ_K for the size of each buffer in KB. While the above version uses values 2 and 512 respectively, I wanted to know if different values for those constants would result in better performance. To do this I modified the constant declarations to look for environment variables if available, as follows:
|
|
After setting up a wrapper script to which I could provide the values as parameters, I ran a benchmark parameterizing IO_CAP over 2,3,4 and IO_BUFSZ_KB over 256,512,1024,2048. The table below shows the performance (mean time) for the various combinations:
IO_CAP |
IO_BUFSZ_KB |
mean (s) | stddev |
|---|---|---|---|
| 2 | 256 | 1.107 | 0.029 |
| 3 | 256 | 1.143 | 0.049 |
| 4 | 256 | 1.113 | 0.010 |
| 2 | 512 | 1.011 | 0.024 |
| 3 | 512 | 0.983 | 0.009 |
| 4 | 512 | 1.057 | 0.143 |
| 2 | 1024 | 0.991 | 0.050 |
| 3 | 1024 | 1.061 | 0.039 |
| 4 | 1024 | 1.100 | 0.113 |
| 2 | 2048 | 1.084 | 0.029 |
| 3 | 2048 | 0.972 | 0.006 |
| 4 | 2048 | 1.016 | 0.008 |
Using two threads, one for I/O and one for counting, the best run this time was using 3 x 2MB buffers, with the following detailed performance time:
|
|
Still, it isn’t much of a range and with an average across the different configurations of 1.0535s, we’re running ~7x faster than wc -l.
More cores, more threads
Since my test machine has 6 cores, doubling to 12 with hyper-threading enabled, the next optimization is to try and leverage all those cores. Counting lines is inherently parallelizable, by which I mean that I can split and count the file in any order and the sum of the lines in each buffer will add up the total number in the file.
If you were wondering earlier why I even bothered with the two threads separating I/O and counting, it was because of simplicity. Concurrent data processing is fraught with many potential perils, not the least of which are race conditions due to shared resources. Keeping I/O in one thread and counting in the other meant we were running two sequential tasks that didn’t have much to worry about on their own.
The next version, however, runs NUM_PAR fibres (based on the number of CRYSTAL_WORKERS threads set up by Crystal’s multi-threading runtime) where each reads and counts IO_BUFSZ-byte chunks from the file. The reading offset if calculated so that each thread skips NUM_PAR chunks from their initial offset, essentially moving through the file like a wave.
|
|
Using 12 threads and a 512KB buffer per thread (total of 6MB of memory), we have the following benchmark result counting half a billion lines:
|
|
Wham! Using multiple threads and harnessing all the cores we are now ~3.3x faster than when we just separated I/O from counting, and compared to wc -l the parallel line counter is ~23x faster!
Summary of benchmarks
The following environment variables were set prior to running the benchmarks to ensure that the two multi-threaded versions were run with specific concurrency configurations.
|
|
The multi-threaded parallel line counter, bin/lc_byte_slice_wide8_par, compared to all the other versions, ran
| times | faster than |
|---|---|
| 3.37 ± 0.05 x | bin/lc_byte_slice_wide8_bgio |
| 5.03 ± 0.03 x | bin/lc_byte_slice_wide8 |
| 5.38 ± 0.03 x | bin/lc_byte_slice_wide |
| 21.67 ± 0.12 x | bin/lc_byte_slices |
| 23.19 ± 0.14 x | wc -l |
| 42.25 ± 0.19 x | bin/lc_bytes |
| 52.50 ± 0.43 x | bin/lc_string_lines |
| 154.99 ± 0.64 x | bin/lc_chars |
Conclusion
It should be no surprise by now that the simplest and most intuitive programs are not also the fastest. The increasing code complexity comes from us understanding how things work and unwrapping the abstractions that on one hand made it so easy to get the job done simply while on the hand paying the price in performance.
Of course, if most of your files are small, just use the simpler program and instead use the GNU parallel7 command to run it in parallel across many files.
With very large data files, however, it is really satisfying to dig into the details of how things work and figure out a way to optimize a program until it is ~155 times faster than the first one that got the job done. After all, isn’t it amazing that a 6GB file with 500 millions lines can be counted in less than a third of a second?
Feedback and thoughtful discussion welcome here in the Crystal Forum
Furthermore
Here I address some questions and topics that didn’t neatly fit into the content above.
- It may seem surprising, given its pedigree and vintage, that
wchasn’t already made improvements that were outlined above. As pointed out in the community feedback,wcdoes indeed have various optimizations (see here and here) including the use ofmemchras well as AVX/SIMD operations. Since these appear to apply only when certain criteria are met (e.g. line length), they appear not have kicked in since the test file I used had 500 million lines that didn’t meet the criteria, or perhaps for some other reason. - Nonetheless, I want to reiterate that this post is not intended to denigrate
wcbut rather use it as a well known baseline for the exercise of showing how more and more optimisation, which is a fun activity in itself, often leads away from intuitive code towards more complicated programs.
-
Crystal is a compiled statically-typed language with Ruby-inspired syntax. ↩︎
-
Per Unicode 15’s chapter on “Encoding Forms”: The UTF-8 encoding form maintains transparency for all of the ASCII code points (0x00..0x7F). That means Unicode code points U+0000..U+007F are converted to single bytes 0x00..0x7F in UTF-8 and are thus indistinguishable from ASCII itself. Furthermore, the values 0x00..0x7F do not appear in any byte for the representation of any other Unicode code point, so that there can be no ambiguity. ↩︎
-
All performance testing was done with
hyperfineusing 2 warm-up runs followed by 5 measured runs, each separated bysleep 5, with a 6.4GB data file containing 500 million lines. ↩︎ -
I tried a number of buffer sizes and found that after 1MB it started to take longer due to blocking file I/O taking longer than the time count the newlines in each chunk. ↩︎
-
Here’s the link to patches in the Linux kernel mailing list: https://lore.kernel.org/lkml/[email protected]/T/#u ↩︎
-
“GNU parallel is a shell tool for executing jobs in parallel using one or more computers.” See here. ↩︎